
A to Z of Excel Functions: The FISHERINV Function
12 July 2019
Welcome back to our regular A to Z of Excel Functions blog. Today we look at the FISHERINV function.
Correlation coefficients are used in statistics to measure how strong a relationship is between two variables. There are several types of correlation coefficient: Pearson’s correlation (also called Pearson’s R) is a correlation coefficient commonly used in linear regression. If you’re starting out in statistics, you’ll probably learn about Pearson’s R first. In fact, when anyone refers to the correlation coefficient, they are usually talking about Pearson’s R.
Correlation coefficient formulas are used to find how strong a relationship is between data. The formulas return a value between -1 and 1, where:
- 1 indicates a strong positive relationship (as one variable increases, so does the other generally)
- -1 indicates a strong negative relationship (as one variable increases, the other decreases generally)
- a result of zero (0) indicates no relationship at all.
Examples of correlation coefficients are as follows:

To be clear:
- a correlation coefficient of 1 means that for every positive increase in one variable, there is a positive increase of a fixed proportion in the other. For example, shoe sizes go up in (almost) perfect correlation with foot length
- a correlation coefficient of -1 means that for every positive increase in one variable, there is a negative decrease of a fixed proportion in the other. For example, the amount of gas in a tank decreases in (almost) perfect correlation with distance travelled since last filling the tank
- zero means that for every increase, there isn’t a positive or negative increase; the two variables just aren’t related.
The absolute value of the correlation coefficient gives us the relationship strength. The larger the number, the stronger the relationship. For example, |-.75| = .75, which has a stronger relationship than .65 even though this is positive.
There are several types of correlation coefficient formulas. One of the most commonly used formulas in stats is Pearson’s correlation coefficient formula. Given a set of n bivariate sample pairs (xi, yi), i = 1, ..., n, the sample correlation coefficient r is given by
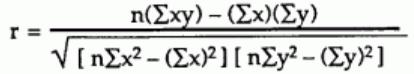
The correlation between sets of data is a measure of how well they are related. The most common measure of correlation in stats is this Pearson Correlation. The full name is the Pearson Product Moment Correlation (PPMC). It shows the linear relationship between two sets of data. In simple terms, it answers the question, can I draw a line graph to represent the data? Two letters are used to represent the Pearson correlation: Greek letter rho (ρ) for a population and the letter “r” for a sample.
To understand how this fits in with the FISHER function, let’s consider a sampling distribution. This is a graph of a statistic for your sample data. Common examples include:
- mean
- mean absolute value of the deviation from the mean
- range
- standard deviation of the sample
- unbiased estimate of variance
- variance of the sample.
Most commonly when using charts we plot numbers. For example, you might have graphed a data set and found it follows the shape of a normal distribution with a mean score of 100. Where probability distributions differ is that you aren’t working with a single set of numbers; you’re dealing with multiple statistics for multiple sets of numbers. If you find that concept hard to grasp: you aren’t alone.
While most people can imagine what the graph of a set of numbers looks like, it’s much more difficult to imagine what stacks of, say, averages look like.
Let’s start with a mean, like heights of financial modellers. Like many things in nature, heights follow a bell curve shape. Let’s say the average height was 5’9″ (sorry, I am a Brit and I still think in feet and inches). If you had 10 modellers, you might get 5’9″, 5’8″, 5’10”, 5’9″, 5’7″, 5’9″, 5’9″, 5’10”, 5’7″, and 5’9″. The distribution of small samples may vary significantly (e.g. uniform or “scattered”), but for larger datasets, there is a mathematical trick we may employ.
In statistics, the Central Limit Theorem tells us that if you have lots of data, if you plot the average of these averages it will eventually approximate to a good, old-fashioned bell curve. That’s the basis behind a sampling distribution: you take your average (or another statistic, like the variance) and you plot those statistics on a graph.
The Fisher Z-Transformation is simply a way to transform the sampling distribution of Pearson’s r (i.e. the correlation coefficient) so that it becomes normally distributed. The “z” in Fisher Z stands for a z-score, and the formula to transform r to a z-score is given by
z’ = .5 [ln(1 + r) – ln(1 – r)].
This is what the FISHER function does. The FISHERINV function is the inverse of this transformation, i.e. if y = FISHER(x), then x = FISHERINV(y). The formula is given by
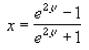
The FISHERINV function employs the following syntax to operate:
FISHERINV(y)
The FISHERINV function has the following argument:
- y: this is required and represents the numeric value for which you want to perform the inverse of the Fisher transformation.
It should be noted that:
- if y is nonnumeric, FISHERINV returns the #VALUE! error value.
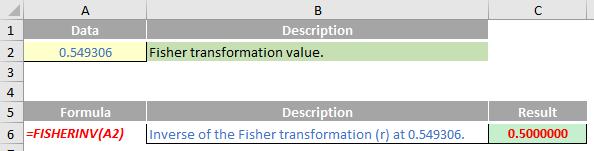
Please see my example below:
We’ll continue our A to Z of Excel Functions soon. Keep checking back – there’s a new blog post every business day.
A full page of the function articles can be found here.