
Power BI Blog: Just Speculate Over Numbers - Part 1
3 May 2018
JSON (or JavaScript Oject Notation) is a free file format used data transfer similar to XML. Instead of using text mark-up notation, it uses a subset of the JavaScript language. The JSON format is often preferred in newer web applications over XML because it is more lightweight. Read this great Guide to JSON in 3 minutes for an in-depth comparison between JSON and XML.
The reason why JSON is preferred in modern applications is that it is more lightweight than XML as it uses metadata i.e. data that describes and gives information about other data. The JSON file starts with a description of the file and details the information about the columns in the data. Then the data is then simply output to an array.
We’re going to be using the New York Lottery Powerball results and payouts information. This is available in JSON format here. Download the file and save it locally on your computer.
If we view the JSON data in a text editor, this is what will appear:
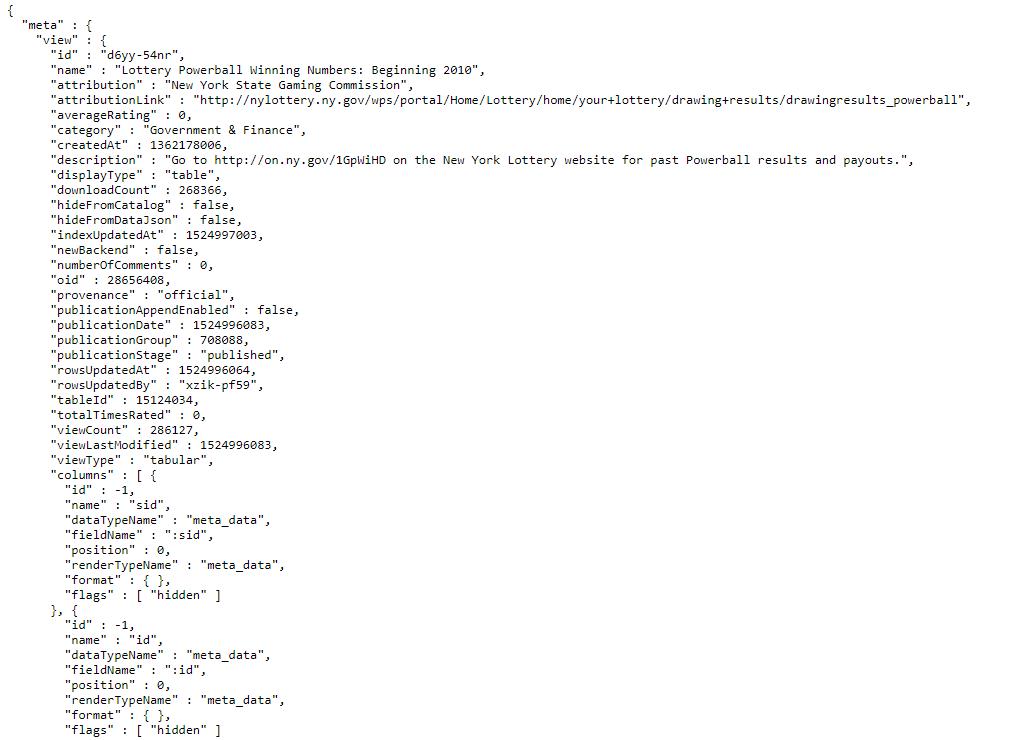
Notice that the first section is called “meta” which carries the metadata. This describes what the dataset is and how it is structured.
Scrolling down after the “meta” section is closed off we can see this:

The “data” section contains the actual data. Notice how it’s been put in rows with no description of what each individual item is. This is the key difference to XML files used in our previous exercise. Because there is no descriptor before each item it shrinks the file size, thereby making it more “lightweight”
Now we’re comfortable with the structure of our JSON file, let’s import it using “Get Data” selecting the “JSON” option:
Select and open your file. Unlike the other imports, it will bring you straight to the Power Query Editor instead of previewing the file and allowing you to choose “Load” or “Edit”.

Notice how the fields are yellow. This means that you can “navigate” and click through to drill down. The metadata is separate to the actual data so we’re going to have to split them. Firstly, duplicate the query so it accesses the same source - we will use the two queries to navigate through to the components of the file. One query to focus on parsing the “meta” section and the other on the “data” section.
To duplicate the query, just right click on the query on the “Queries” pane.
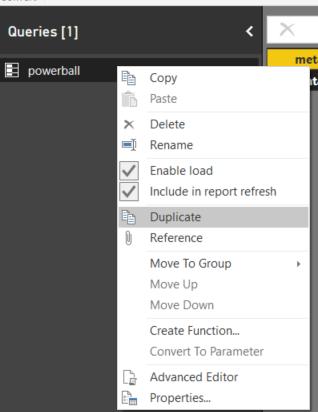
I’m going to rename the first one “Metadata” and the second one “Dataset” to be clear which query will focus on what parts.
Great! Now we’re ready to start performing transformations. We will step through the data cleansing process next week by going through Dataset.
Tune in next week for more Power BI Tips!